
By now many of you likely have received a barrage of GPDR emails, some more humorous and some drier than cardboard. I hope these emails have helped spread awareness of digital privacy. I’m looking forward to reaping some indirect benefits on the sideline as a citizen in a surveillance state, because for most companies, it’s easier to adopt the same set of policy across the globe than a different one for each region. This spill-over effect of the new EU privilege is much welcomed.
Tangentially, the number of data breaches and leaks headlined in the news seems to be on a rise over the past few years—all the more reason to support companies with transparent, respectful, and vigilant data practices. Meanwhile, it’s also always good to be cautious. So the question I asked myself then was twofold; first: why do I need to protect my data? And second: how do I develop a strategy against potential threats to my data?
The first question led me to reading up on the “I have nothing to hide” argument and its implication on privacy development. It’s about the subtle nuance of agency: “I have nothing to hide” is fundamentally different from “I have nothing I want to show you.” The former implies that a person has no reason to not expose everything unless there’s something nefarious going on, shifting the agency of data control to a non-owner. The latter rightfully associates the agency of data control to its owner, implying that sharing is a willful action, not an expectation. If we’re talking about privacy as a right, each citizen should be able to decide what to share, not whether to hide. The nothing-to-hide argument short-circuits that logic to halt critical thinking around privacy and stifle public discussion.
My thinking around data protection stems from this distinction: I am the owner of my data and I should give explicit permission for the harvesting and use of my data. By not protecting my data, I lose my ability to control it, and relinquish that power to someone else.
The next question then naturally becomes: how do I develop a strategy against potential threats to my data? The four threat models I considered are, in order of increasing difficulty and decreasing likelihood: personalized advertising, targeted attack, data breach, and government operation.
Personalized advertising at its core is manipulation at scale, possible under loose data regulation for the sole purpose of making profit. No human brain can avoid the effects of persuasive psychology, but we can at least reduce our exposure to it. On the other end of the spectrum, you are basically powerless against a government-sponsored attack, where whatever little laws of privacy that exist no longer apply to you. Neither of these two threat models is the subject of writing here.
How can I proactively defend against data abuse in the other two models: targeted attacks and data breaches? The obvious solution for both is to never put anything “out there,” but in this modern day and age, especially for knowledge workers, a Luddite approach to privacy is not practical.
Targeted Attacks
If you have a habit of oversharing on the web, chances are that someone with the dedication and determination could piece together a profile of you to impersonate you and get access to your accounts. Without two-factor authentication and proper caution by your data custodians, targeted attacks are surprisingly easy. Maybe Jealous James on your Facebook learned about your big bonus and pieced together answers to your security questions to “recover” your password to your bank account. Full names, birthdays, phone numbers, and personal details are floating out there, getting exchanged through multiple hands outside of our control.
Personally, I can’t do over my online life from when I first started using the Internet, so I choose to embrace the inevitable exposure and follow a good rule of thumb: never share the same login/username between accounts that expose your real identity and ones that don’t. In other words, if an app or service shows your login email to the public along with your identity information, you should not use that same email to log into your bank. Some common sense and caution when sharing personal details can make targeted attacks much harder. However, such measures are useless when servers are compromised.
Data Breaches
What if an attacker already has access to a compromised server? I spent some time thinking about the more catastrophic case. For the sake of this thought exercise, let’s adopt Murphy’s Law: assume every bit of information you put online is going to be stolen at some point (with the exception of E2EE where you have complete control over your private key, in which case, stolen data would be jumbled and useless).
If we categorize all the services we use by how we sign in and what information they expose, we end up with two axes: LoginID, which is whatever username/email you use to log into the service, and PII, or Personally Identifiable Information (credit card, delivery address, resume, photo, etc.). When leaked, one or both pieces of that information from one service can lead to an attempted attack into another service.
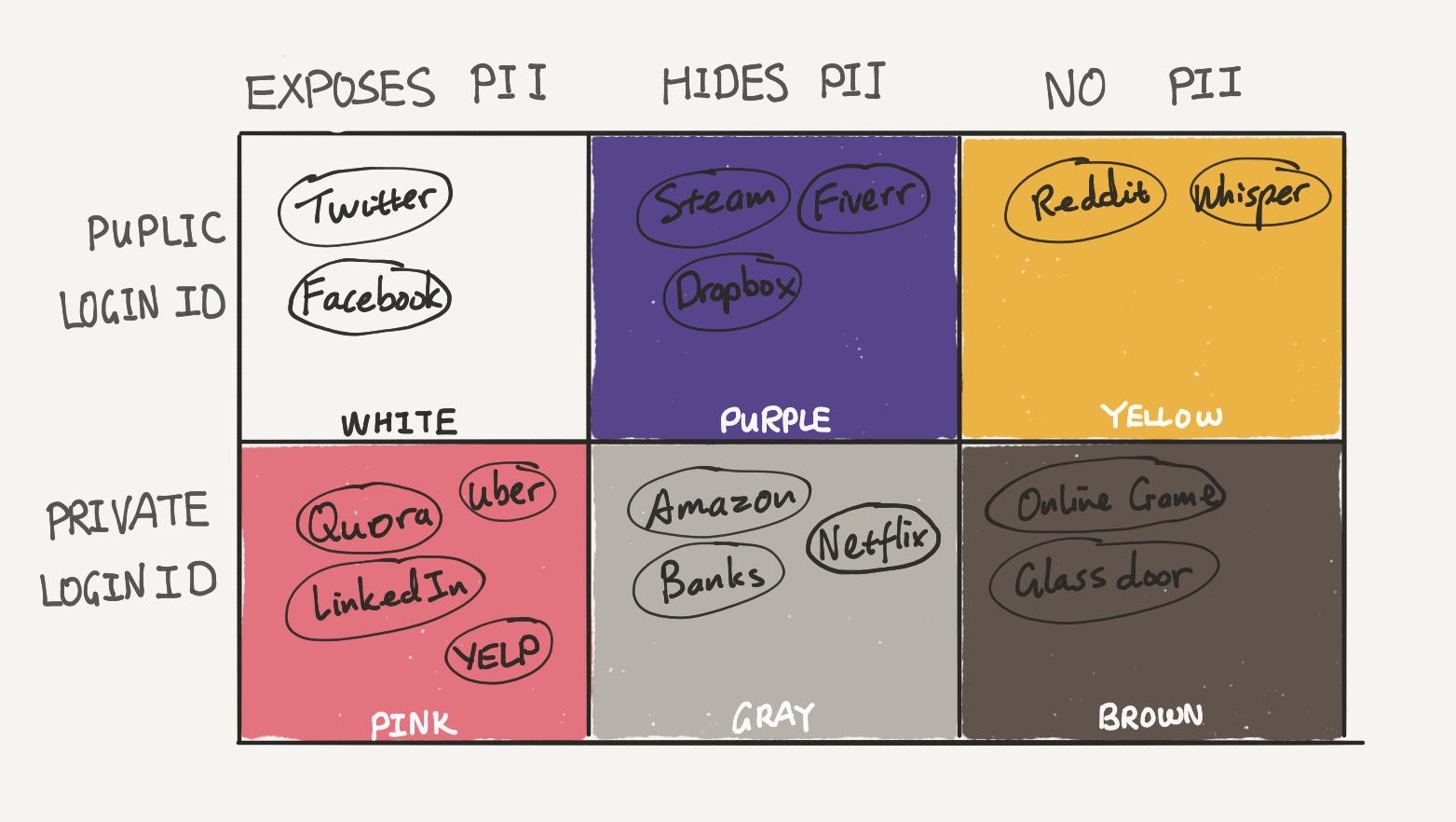
In this chart, the “Public LoginID” row contains services that expose your login/username to the public. Twitter is a good example of such a service, where your handle is both your public identity and your LoginID. Services in the “Private LoginID” row hide the means with which you sign in.
Moving on to the columns: sites in “Exposes PII” like Facebook and Quora expose your PII (like names, birthdays, addresses). Sites like Amazon or iTunes in the “Hides PII” columns privately store PII like credit cards and delivery addresses. Services in “No PII” essentially do not require any PII from you, such as games or Reddit accounts.
Let’s assume Cautious Caroline currently uses the same Login ID J for all of the above and plots them on this table.

Immediately, applying our rule of thumb for targeted attacks from above, we can firewall the “Exposes PII” column from the rest. For better protection, Caroline should use a new email address, A, for columns two and three.
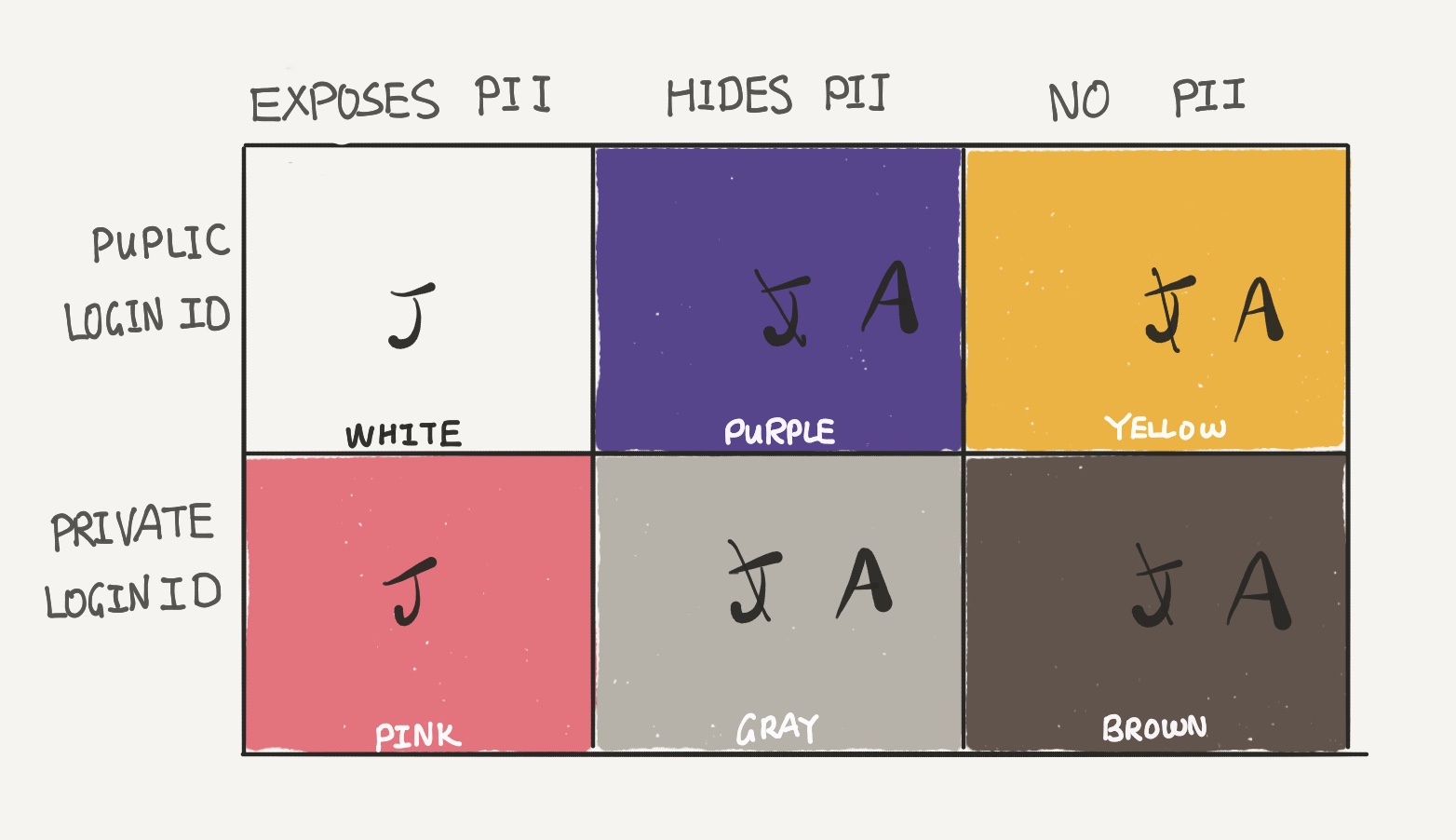
Now, in Row 1, even without breaching the server, the attacker is able to use the public LoginID to attempt an attack on Pink, Gray, and Brown services in Row 2. Therefore, Row 1 and Row 2 must use different LoginID’s. Caroline proceeds to change services in Row 2 to use LoginID B.
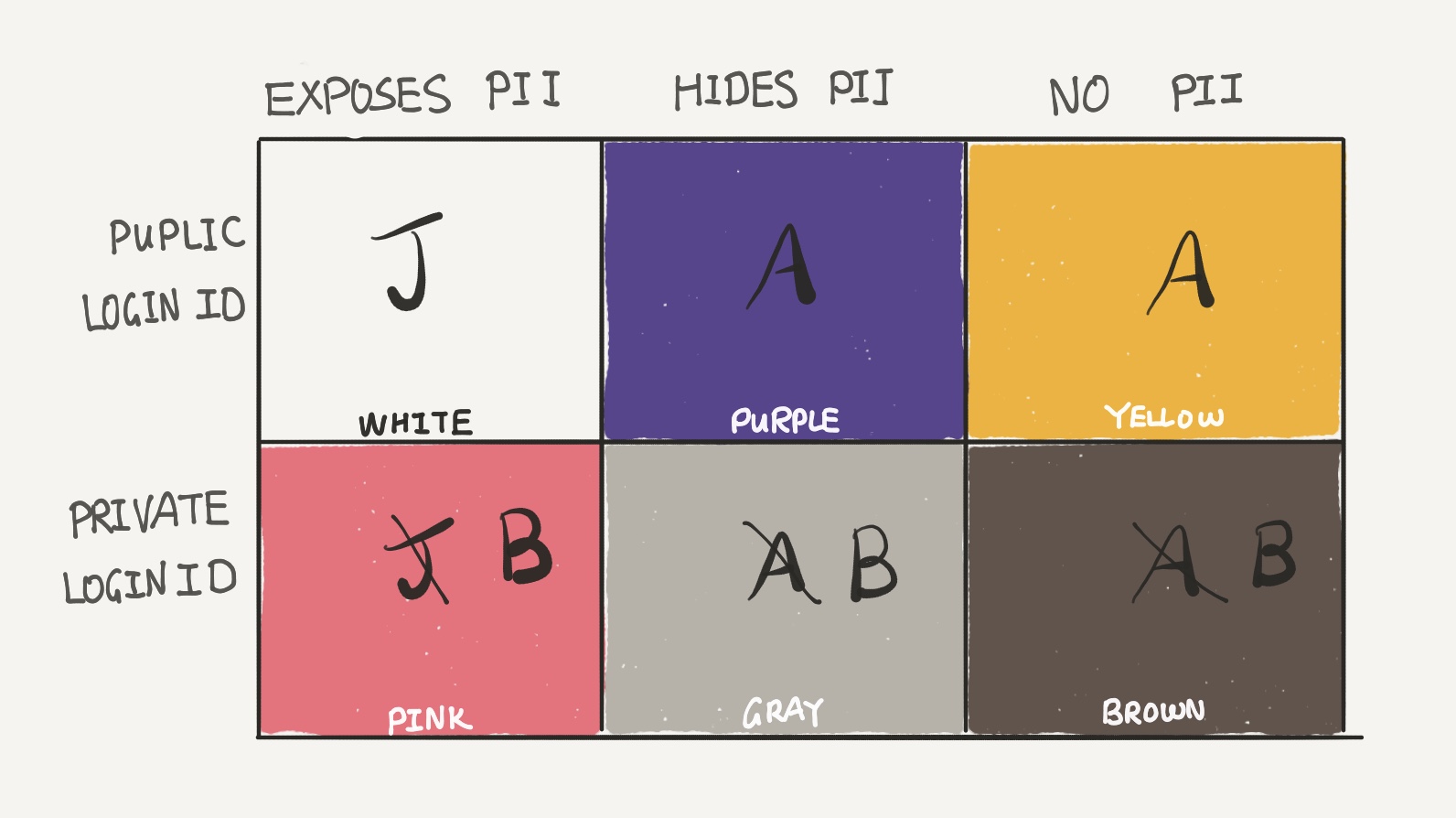
Let’s take a look at the Yellow box. An attacker can attempt to reveal the PII behind a virtual identity by using the same LoginID A from Yellow on services in Purple. Therefore, Caroline needs to use a different LoginID between Purple and Yellow.
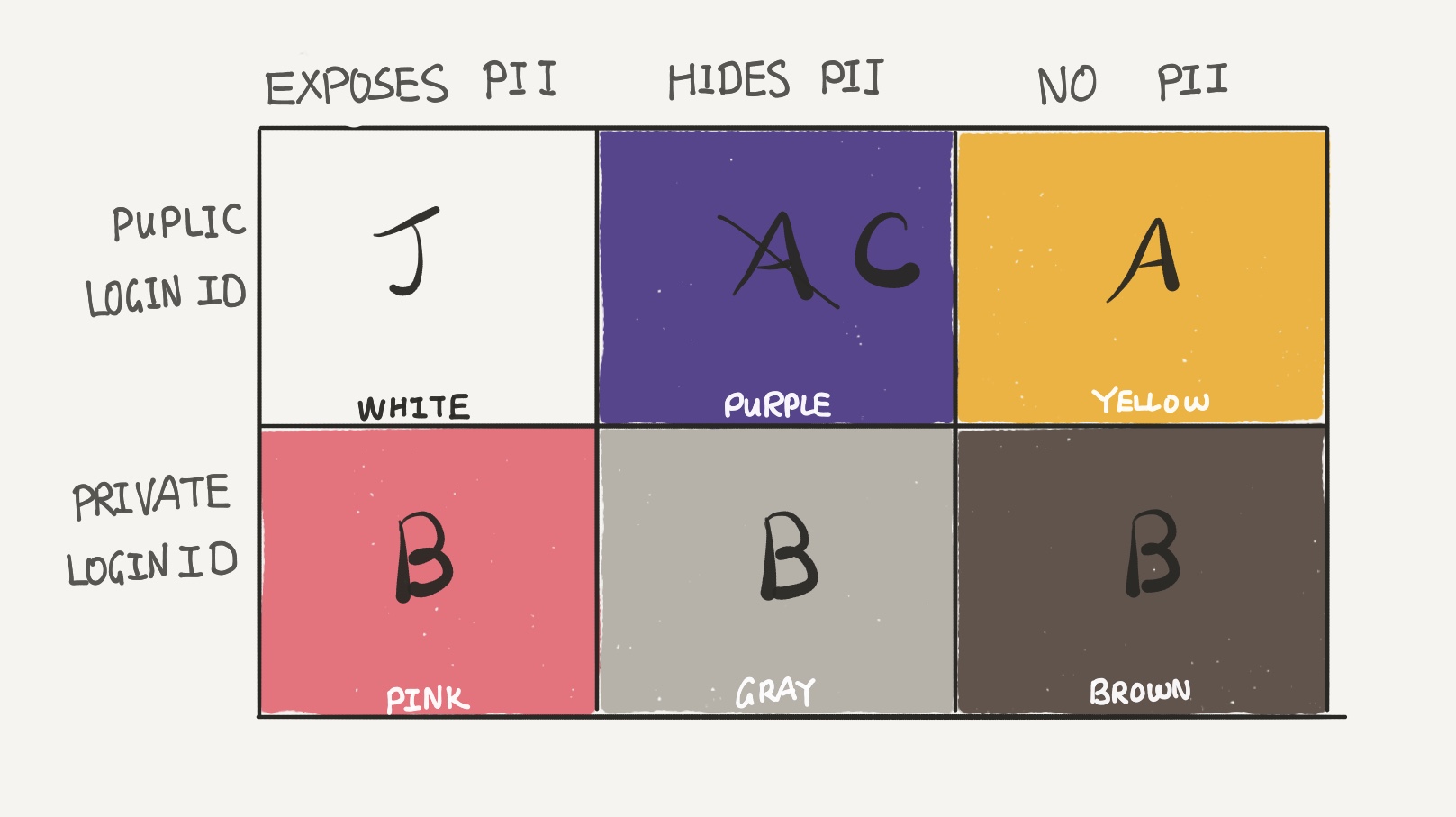
Now, in the case of a breach of a Gray service, the attacker will have both PII and LoginID B, gaining leads to attack Pink and Brown services. It is best for Caroline to use a different LoginID here as well.
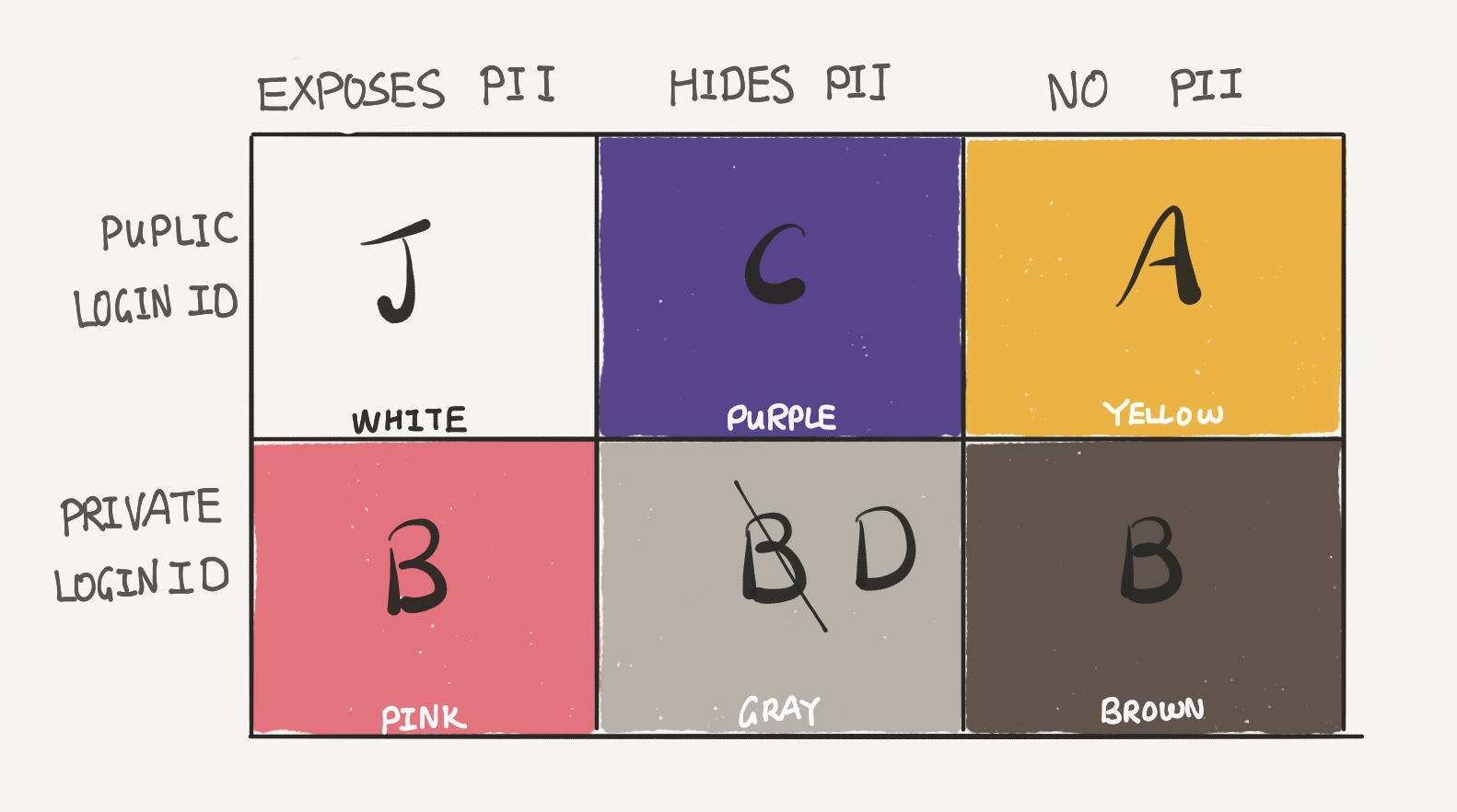
Lastly, if a Brown service is breached, the LoginID can lead the attacker to associate the anonymous data with real PII by attacking Pink services.
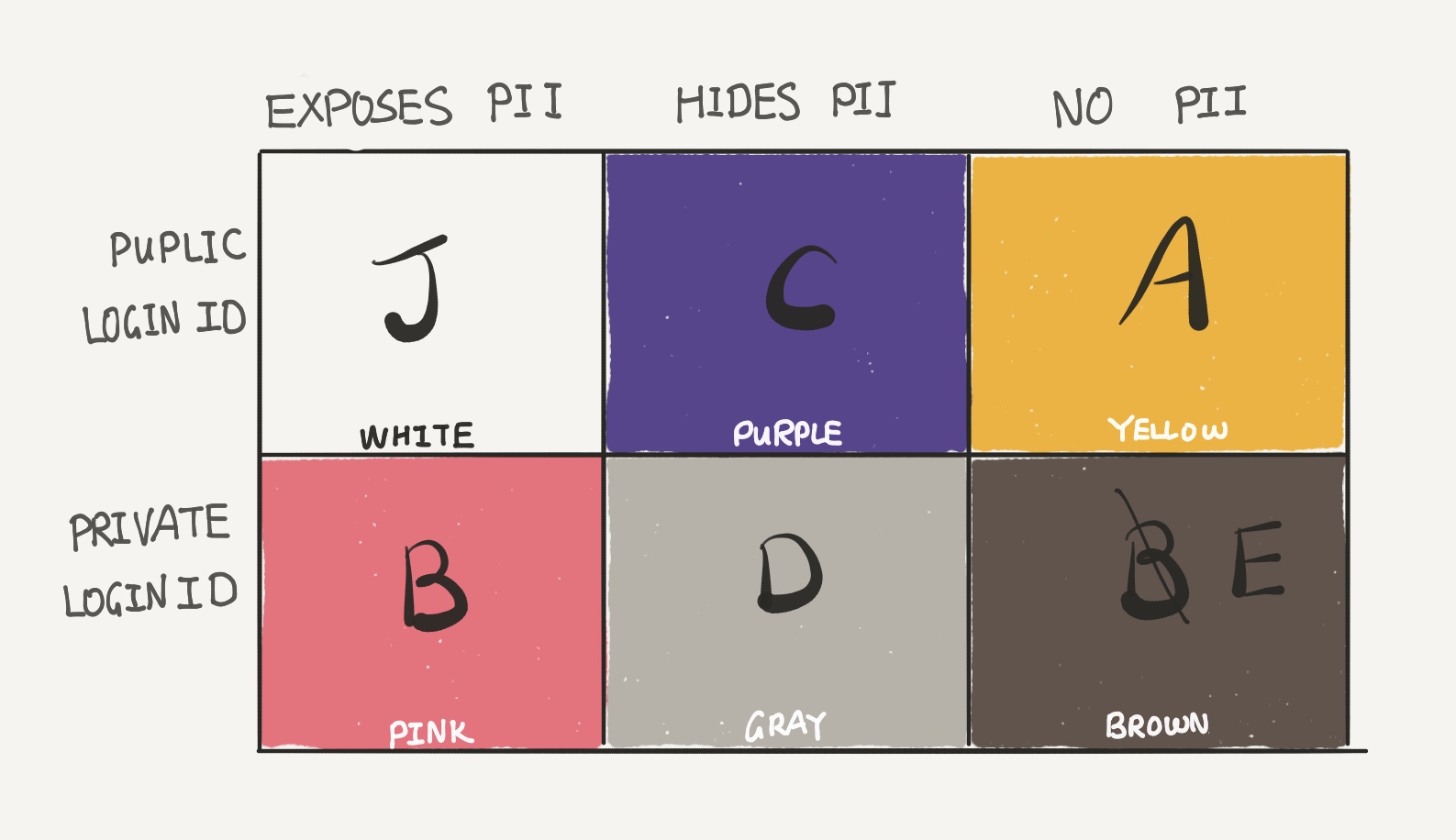
That leads us to the conclusion that for maximum quarantine between different services with varying degrees of exposure risks, it is best to use a different loginID for each colored box.
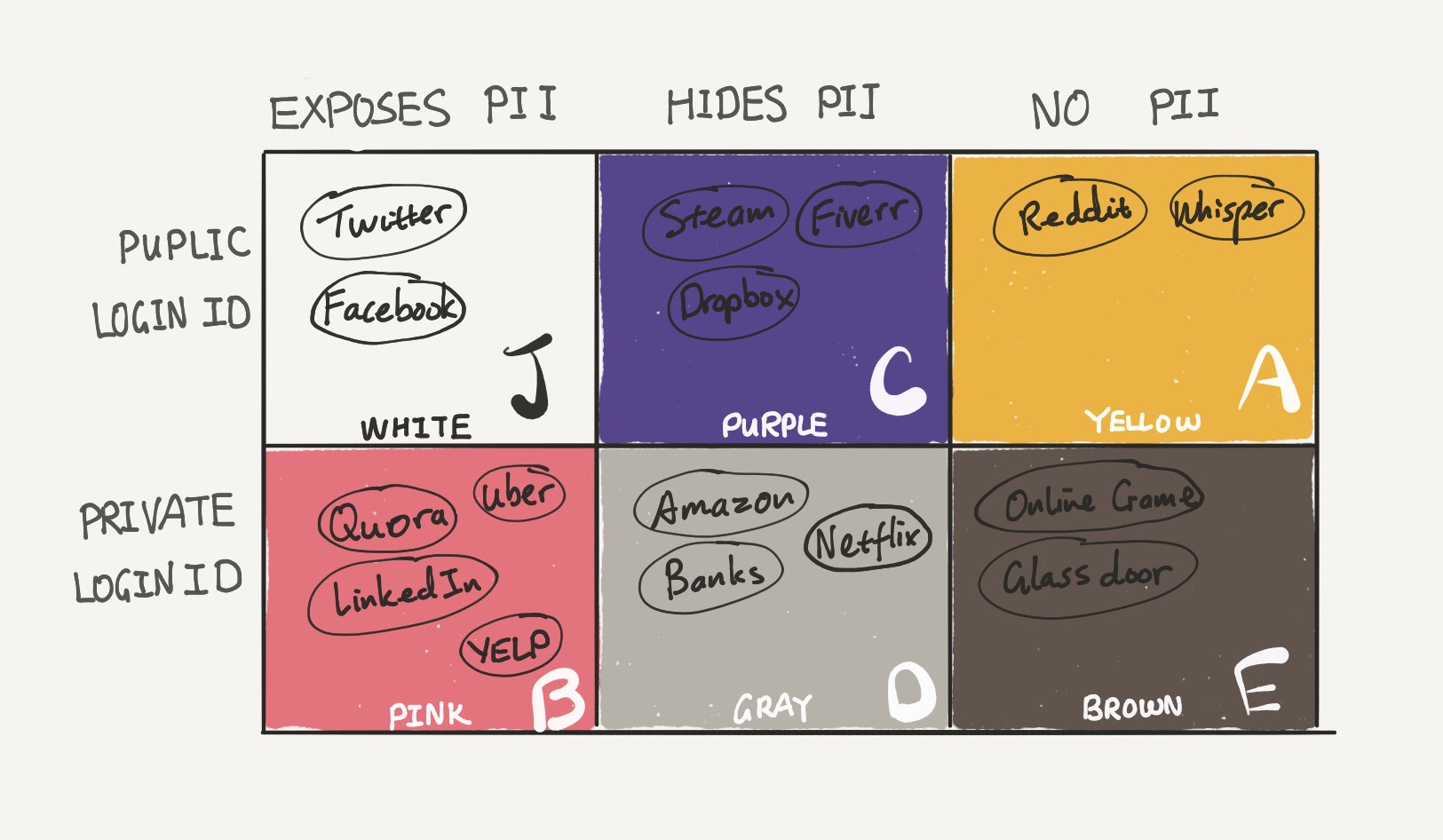
The breach quarantine matrix makes it harder, but not impossible, to perform targeted attack. It also limits the contamination and usefulness of stolen data from the attack’s point of view. But the entire quarantine model also assumes that the only way to obtain PII is either by successfully logging into your account or breaking into your server. In reality, there are dozens of other ways to snoop on you. Furthermore, in an age where every service provider strives to track customer data, there is simply no easy way to avoid real identity exposure. You can use pseudonyms, but inevitably you will end up handing over PII to someone else. You only have one real identity, and it is best to assume that your identity is publicly available to anyone with minimal effort. And remember, one could always break into your house and threaten you with a weapon.
After developing this framework, I felt almost at a loss. Perhaps the best benefit of this evaluative framework is a principled way to assess apps and services that ask for your information—a mental exercise before opening up a new attack surface.
Is that worthwhile? Time will tell.